Чуть больше года я веду рабочие заметки на книжке BOOX — совещания, наброски решений, мысли по ходу дня. Писать от руки на e-ink удобно, это не вырывает из потока, но заметки остаются заперты внутри книжки. Хотелось, чтобы они сами попадали в Obsidian и искались по тексту: через полгода удобно найти поиском, почему мы приняли то или иное решение, а не листать “стопку” рукописных страниц.
Чего хотелось
- Создал заметку на книжке — она сама оказалась в нужной папке Obsidian.
- Минимум ручных действий, никаких «экспортировать -> перекинуть -> разложить».
- Полнотекстовый поиск, то есть рукописный текст надо ещё и распознать.
Заход первый: штатные средства
BOOX умеет синхронизировать заметки в облако, в том числе в свой Nextcloud. Я настроил синхронизацию, но дальше файлы надо было как-то перекладывать по нужным папкам — получалась громоздкая цепочка.
Второй вариант — Syncthing плюс скрипты, которые реагируют на новые файлы. Вышло сложно и хрупко, много движущихся частей. Вдобавок Syncthing на книжке ел батарейку, постоянно вися в фоне. В обоих случаях получался слишком большой friction между инструментом и полезным опытом.
Заход второй: WebDAV как транспорт
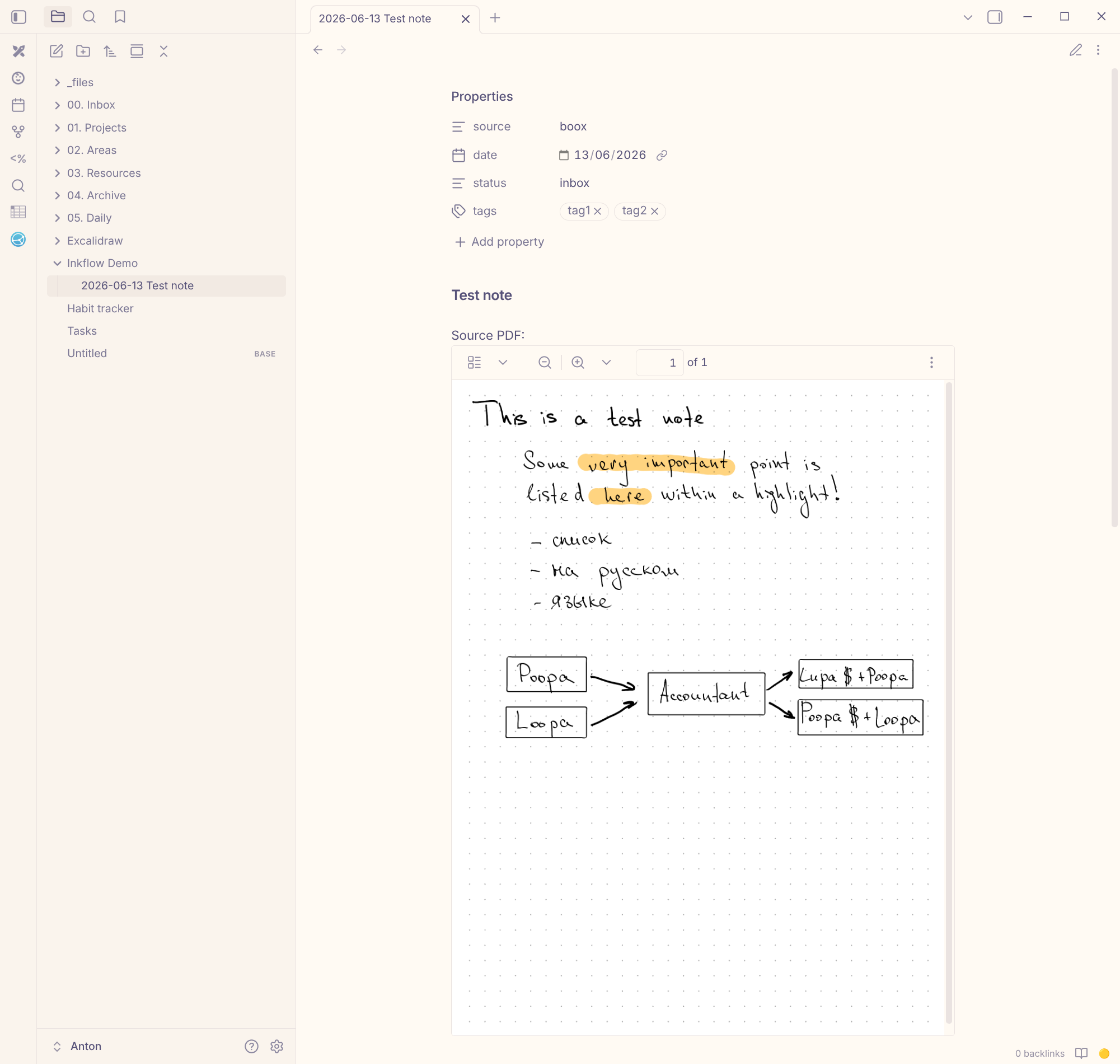
Поразмышляв, какое решение было бы идеальным, я пришёл к очень простому. Книжка умеет «отправлять заметки в облако» по протоколу WebDAV. Вместо того чтобы встраиваться где-то после облака, можно самому притвориться облаком: поднять свой WebDAV-сервер. Книжка думает, что заливает PDF в хранилище, а на деле файл попадает к моему обработчику. Протокол становится просто транспортом, вся логика — на моей стороне, а на книжке всё остаётся штатным, без сторонних приложений.
Чтобы понять, что именно шлёт книжка, сначала поднял заглушку, которая только логировала запросы. Оказалось, всё сводится к двум действиям: осмотреть папку и залить файл. Дальше осталось написать настоящую реализацию — inkflow. Он принимает PDF и раскладывает по vault’у: файл попадает в нужную папку Obsidian, рядом создаётся markdown-заметка по шаблону. Дату и теги проставляю прямо на книжке при создании заметки, inkflow берёт их из имени файла.

Заработало: заметки сами раскладывались по местам, рядом лежал PDF. Не хватало поиска.
Заход третий: распознавание текста
Чтобы искать по заметкам, рукописный текст надо распознать.
Классический OCR (Tesseract и подобные) с рукописным текстом справляется плохо, с русским — совсем. Локальные LLM через Ollama тоже не пошли: точность низкая, на страницу уходит слишком много времени.
А онлайн-LLM решают задачу отлично. Остановился на Gemini — лимиты на API щедрые, должно хватить даже бесплатного тарифа. inkflow отправляет туда PDF и получает обратно распознанный текст.
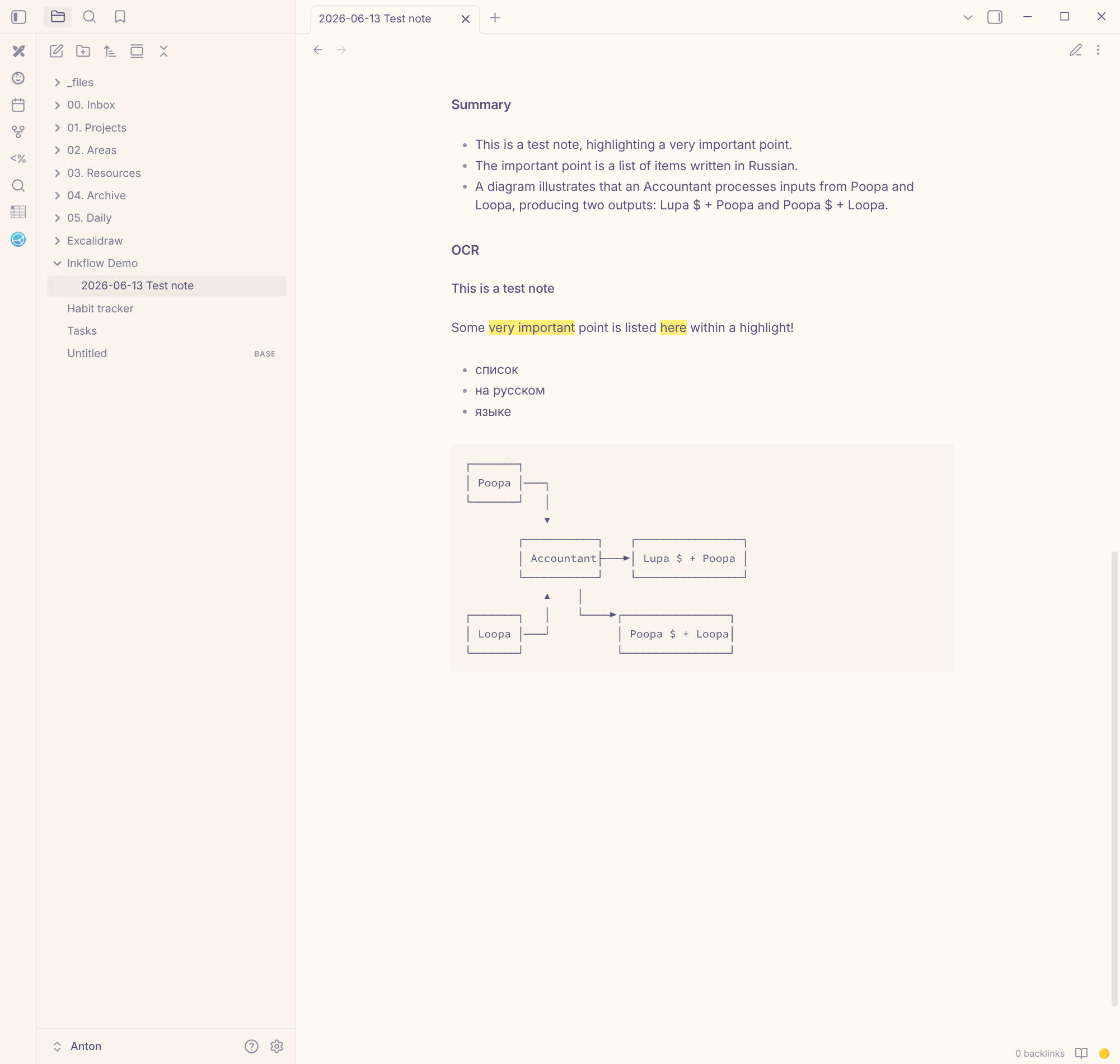
Причём LLM делает больше, чем OCR. Классическое распознавание вернуло бы простыню текста, а модель понимает структуру страницы и переносит её в markdown: выделенное маркером оборачивает в ==…==, обведённое в рамку делает жирным, рисованные чекбоксы превращает в - [ ]. Ко всему этому короткое саммари с основными пунктами.
В Obsidian рядом лежат исходный PDF и распознанная заметка (на один скрин целиком не влезла):
Приватность
Один нюанс: данные с бесплатного тарифа Gemini Google может использовать для обучения. Для рабочих заметок не подходит. На платном API данные в обучение не уходят, а стоит он копейки — при 5–10 страницах в день выходит меньше половины евро в месяц. Это дешевле и лучше, чем поддерживать локальное распознавание, которое всё равно работало хуже.
Вывод
Неприятно признавать, но self-hosted иногда выходит дороже, по времени на настройку и поддержку и по качеству, чем готовый сторонний сервис.
Я прошёл весь круг: облачная синхронизация, Syncthing со скриптами, локальный OCR, локальные LLM. Лучше всего сработал гибрид: своя прослойка там, где нужен контроль и нативный UX, и платный сервис там, где он объективно лучше и стоит копейки.
И сами заметки — это удобно. Стало заметно легче не терять контекст по принятым решениям: нужное просто находится поиском.
Код: pltanton/inkflow.